Einleitung und Fragestellung
Mittlerweile ist es schon fast ein Jahr her, dass ich meine Abschlussarbeit für den Master of Arts in Internationaler Kriminologie eingereicht habe, da bereue ich immer noch, dass ich meine Arbeit nicht publiziert habe. Einerseits war ich unzufrieden mit meiner Arbeit und andererseits gab es hierfür rechtliche Gründe. Meine Befunde aber nicht zu teilen und in die öffentliche Diskussion einzubringen, widerspricht allerdings meinem Selbstverständnis. Ich nutze also diesen Weg, um aufgrund meiner Beobachtungen eine kleine Neuauswertung meiner Daten durch- und vorzuführen.
Kern meiner damaligen Argumentation war, dass nicht anzunehmen sei, dass Kriminalität mit und über informationstechnischen Systemen – gemeinhin Cybercrime genannt – weder zufällig verteilt sein kann noch ausschließlich technischer Natur ist. Der Grund warum manche Menschen Opfer werden und andere nicht, kann nicht durch Willkür bestimmt sein. Auch dann nicht, wenn angenommen wird, dass die Ausprägung der Opferwerdung vom Nutzerverhaltens abhängig ist. Vielmehr war ich der Überzeugung, dass neben technischen Faktoren wie Nutzungsdauer und -finesse, auch sanfte Faktoren wie Kultur, Bildung, Geschlecht, etc. eine Rolle spielen müssen.
Um dies zu zeigen, bediente ich mich dem Eurobarometer. Dieses wird regelmäßig von der Europäischen Kommission zur Bestimmung der öffentlichen Meinung in Auftrag gegeben und von TNS Opinion & Social in allen EU-Mitgliedsstaaten durchgeführt (damals 27; mehr Infos hier). Abgefragt wurden in der Erhebung 77.2 unter anderem das Sicherheitsempfinden der Bürger in Bezug auf Internetkriminalität und damit verbunden auch Viktimisierungen unterschiedlicher Art. Teil der Erhebung waren auch allerhand demographischer Angaben, doch gab es nur wenige kulturelle Indikatoren. Als zuverlässigster Indikator kann sicherlich die Nationalität gelten. Besser zu verwerten sind allerdings Sprachfähigkeiten. Abgefragt wurden diese zuletzt in Erhebung 77.1. Die Angaben dort umfassten nicht nur den Ort des Interviews, die Nationalität des/der Befragten und die Sprache in der die Befragung durchgeführt wurde, sondern auch die Muttersprache der/des Befragten, wie gut die Fremdsprachenausbildung war und welche sonstigen Sprachen der Person zumindest verständlich seien.
Nun ist einzuwenden, dass politische Meinungsumfragen, wie das Eurobarometer, den wissenschaftlichen Standards der Kriminologie nur mangelhaft gerecht werden können. Die konkreten Beispiele sind vielfältig und gerade bei den Fragen zur Viktimisierungen besonders offensichtlich. Anstelle festgelegte Zeiträume abzufragen (üblich sind 12 Monate), wurden hier Lebenszeitprävalenzen erhoben. Zudem sind die Fragen – vermutlich aufgrund nationaler Besonderheiten und der Sprachhürde – oft zu schwammig formuliert. Im Ergebnis werden nur in einer einzigen Fragenbatterie sämtliche Details zur persönlichen Viktimisierung erfragt. Die Delikte werden dadurch nur ungefähr umrissen und es wird nicht ersichtlich, ob die „Erfahrung“ mit diesen Delikten auch eine konkrete persönliche Viktimisierung mit einschließt, welche Schäden entstanden und so weiter. Ein weiterer – für mich völlig unverständlicher – Aspekt, sind Abstriche bei der Umsetzung europäische Standards durch das Eurobarometer: Es soll bspw. gleichmäßig in allen nationalen Regionen, den Nomenclature of Units for Territorial Statistics der Ebene 2 (NUTS2 – in Deutschland sind es bspw. die 16 Bundesländer), erhoben werden. Doch sind diese weder in allen Nationalstaaten auf der selben Ebene verzeichnet worden, noch entsprechen sie immer den von Europa präzise definierten Vorgaben. Das gleiche gilt für Sprachkenntnisse, die nicht gemäß Common European Framework of Reference for Languages: Learning, Teaching, Assessment (CEFR) erfasst werden, sondern mittels grober und unreflektierter Selbsteinschätzung abgefragt werden. Damit ist es nicht möglich zu bestimmen, ob die Sprachkenntnisse eines/er Befragten bspw. auf Level C1 oder A3 sind. Und es ist weiterhin weder möglich die durchschnittlichen Sprachkenntnisse noch die Viktimierungsraten je Region noch irgendwelche anderen Daten mit den offiziellen Eurostat-Daten zu kartieren. Allerdings schafft TNS mit ca. 1000 Befragungen pro Mitgliedsland eine riesige Datenbasis, aufgrund derer qualitativ gute Hochrechnungen auf europäischem Level gemacht werden können. Mehr kann ein chronisch unterfinanzierter Masterstudent nicht verlangen.
Methodik
Zur Analyse verwendete ich in der Abschlussarbeit Stata SE. Da dies eine komplett neue Auswertung sein soll, kommt dieses Mal PSPP zum Einsatz, welches eine Open-Source Alternative zu IBMs SPSS darstellt. Aus ästhetischen Gründen bereite ich die Daten dann aber mit MS-Excel auf. Da ich mir PSPP aber erst aneignen musste, bitte ich ausdrücklich um Hinweise und Kritik zu meiner Arbeit.
Zwei wichtige Schritte müssen für die Analyse gemacht werden. Erstens, die beiden Datensätze müssen zusammengeführt werden. Normalerweise geschieht dies mit Staaten, da auf dieser Ebene auch andere Daten (Wirtschaftsindikatoren, Demografie, etc.) aus anderen Datenbanken mit herangezogen werden können. Hier würde das aber die Analyse auf 27 Fälle beschränken, die nicht ausreichend aussagekräftig wären. Folglich werden die Daten auf der vorgeblichen NUTS2-Ebene aggregiert, da hiervon rund 350 zur Verfügung stehen. Da aber in vielen Regionen nur wenige Personen befragt worden sind, muss in einigen Ländern noch weiter vereinfacht werden (z.B. in Nord, Süd, Ost, West und Hauptstadt). Diese Zusammenfassungen sind meist aber bereits vom Eurobarometer zur Verfügung gestellt. Zweitens, muss sich die Analyse auf die Fälle beschränken, die in beiden Stichproben miteinander korrespondieren. Denn es gilt, dass nur diejenigen Personen interessant sind, die in beiden Erhebungen angaben Internetnutzer zu sein. Glücklicherweise ist dies eine Standardfrage im Eurobarometer und in jeder Erhebung vertreten. In Erhebung 77.2 wurde allerdings eine leicht variierte Version zum Nutzerverhalten als Filterfrage genutzt wurde, um die Nicht-Internetnutzer aus der Viktimisierungsbefragung auszuschließen. Deswegen kommt es zu Ungenauigkeiten: Im Vergleich zwischen Filterfrage und Standardfrage in Erhebung 77.2 werden von den 26751 Fällen 81 Befragte abweichend ausgeschlossen, während 269 abweichend mit inbegriffen werden.
Ergebnisse
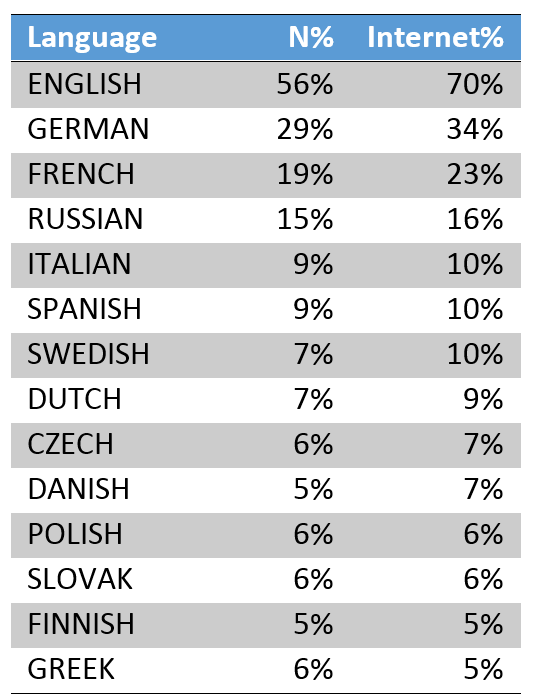
Neben Muttersprachlern sollen hier auch jene berücksichtigt werden, die auch Fähigkeiten aufweisen, die sie selbst als „gut“ oder „sehr gut“ bezeichnen, sowie ausreichend sind, den Medien zu folgen (Presse, Fernsehen oder Internet). Als „fähig“ gelten für diese Analyse somit alle, die angeben eines dieser Kriterien je Sprache zu erfüllen. Um die Analyse nicht zu überfrachten und weitere Ungenauigkeiten zu minimieren, beschränke ich mich auf jene sieben Sprachen die von mindestens zehn Prozent der Internetnutzer (laut Antwortverhalten) beherrscht werden. Dies sind Englisch, Deutsch, Französisch, Russisch, Italienisch, Spanisch und Schwedisch. Außerdem wird Niederländisch mit einbezogen. Die Macher des Eurobarometers führen ebenfalls Englisch, Deutsch, Französisch, Spanisch und Russisch als besonders wichtig an. Das sprachethnographische Forschungsprojekt Ethnologue hebt zusätzlich Chinesisch, Hindi, Arabisch, Portugiesisch, Bengali und Japanisch hervor, da sie zu den 23 meistgesprochenen Sprachen der Welt zählen. Diese sind jedoch unter den annähernd 40 erhobenen Sprachen der Erhebung 77.1 nicht ausreichend stark vertreten, um sie weiter zu berücksichtigen (siehe unten die meist angegebenen Sprachen; n% = Anteil der Stichprobe = 26751 Fälle; Internet% = Anteil der Stichprobe, die das Internet nutzt = 18752 Fälle):
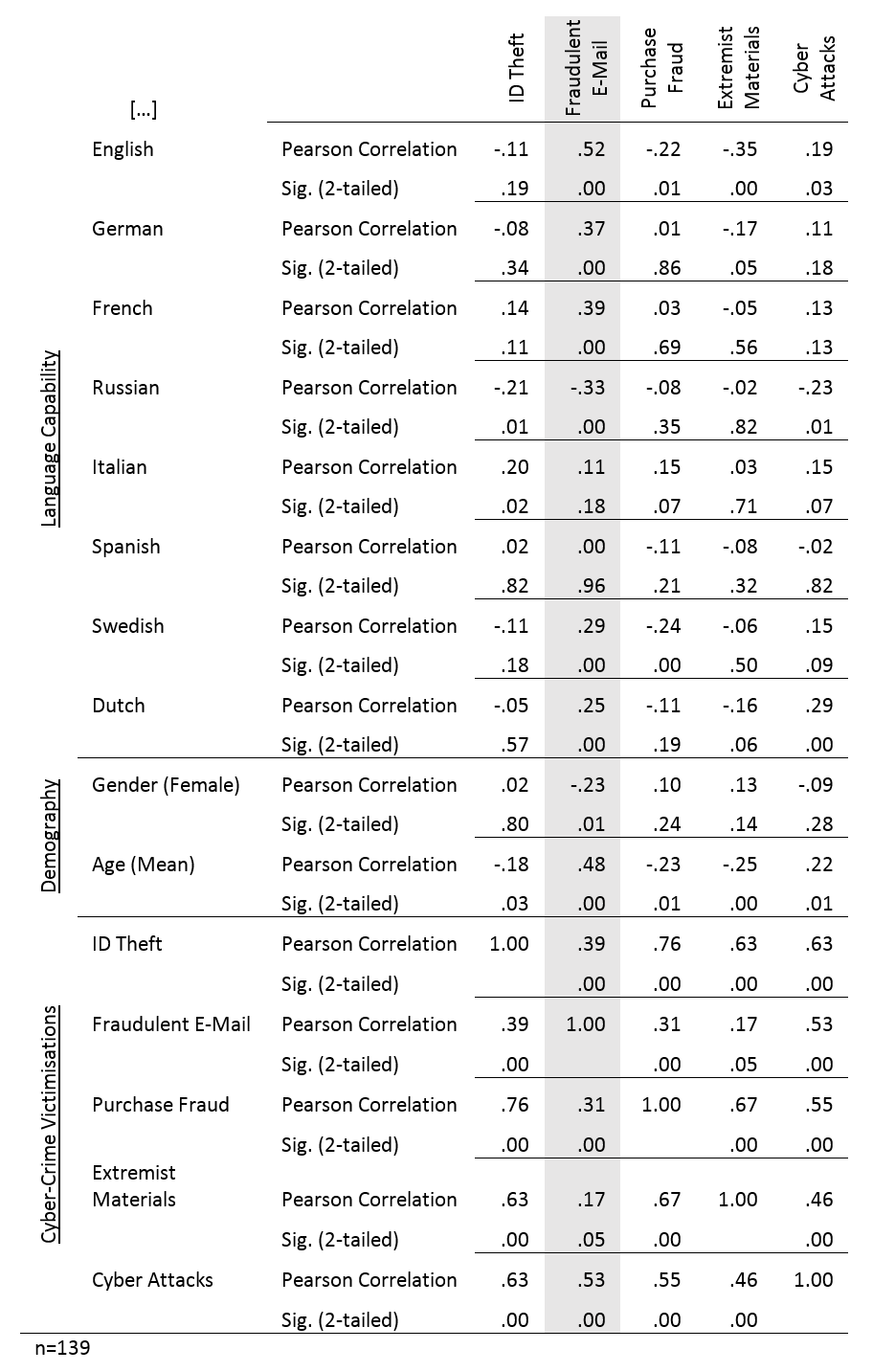
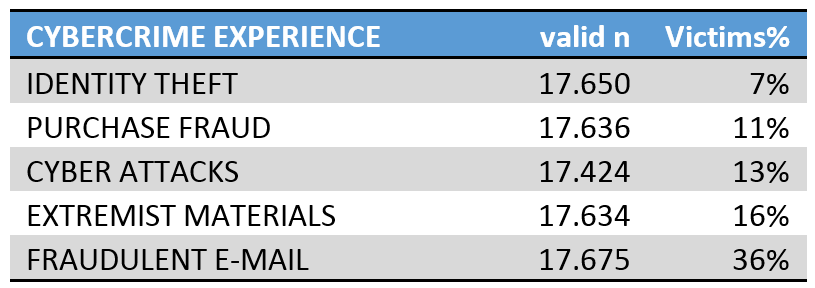
Ich verzichte auf eine multi-variate Auswertung, da die Daten zum einen nicht ausreichend gut erhoben und zum anderen untereinander korrelieren und schief verteilt sind. Statt dessen belasse ich es mit einer einfachen Korrelationsmatrix in die Geschlecht ( = weibl. Anteil) und Durchschnittsalter miteinbezogen sind. Hauptaugenmerk sind aber die fünf in der Erhebung 77.1 abgefragten Viktimisierungen Identitätsdiebstahl, betrügerische E-Mails (Phishing), Handelsbetrug, unbeabsichtigter Kontakt mit politisch extremen Inhalten und der eingeschränkten Nutzbarkeit des Internets aufgrund Cyber-Attacken ((D)DOS-Attacken). Beim Betrachten der Häufigkeitsverteilungen (siehe oben), fällt als erstes auf, wie wenige Viktimisierungen durch die Erhebungen offen gelegt wurden. Angesichts dessen, dass die oben gezeigte Aufstellung ausschließlich Internetnutzer berücksichtigt, ist nämlich selbst der Höchstwert für Phishing-Betroffene (36%) als extrem niedrig einzuschätzen, da das Spam-Aufkommen mit schätzungsweise 29 Milliarden Nachrichten rund 66,4% des Mailverkehrs ausmacht (Symantec, 2014, S. 77ff). Nichtsdestotrotz befinden sich unterstehend die letzten fünf Spalten der Korrelationsmatrix. Der Rest weist zur einen Hälfte spiegelverkehrt identische Werte auf und wertet zur anderen Seite die Korrelationen unter den Sprachen aus, welche hier weniger wichtig sind. Außerdem verzichte ich darauf mich an den Standard zu halten unabhängige Variablen immer über die abhängigen Variablen zu stellen. Denn in diesem Fall werden mit Korrelationen keine Kausalzusammenhänge angezeigt und wäre es andersherum nicht leserlich:

Wie auch schon in meiner Abschlussarbeit gibt es bemerkenswert starke Zusammenhänge bei betrügerischen E-Mails (farblich hervorgehoben). Sie weisen sowohl hohe Korrelationen als auch hohe Signifikanzen auf. Es ist sichtbar, dass bestimmte Sprachen, das Geschlecht und Alter einen erheblichen Einfluss auf die Viktimisierung haben. Gleichzeitig sind Mehrfach-Viktimisierungen stark positiv korreliert. Demnach kommt es bei Populationen mit erhöhtem Englisch, Deutsch oder Französisch sprechenden Bevölkerungsanteilen, als auch bei stark männlich ausgeprägten und alten Bevölkerungen vermehrt zu Phishing-Attacken kommt. In russisch-sprachigen Bevölkerungsgruppen hingegen ist eine deutlich negative Ausprägung zu erkennen. Die Werte zu Italienisch und Spanisch waren nicht ausreichend signifikant. Durchgehend signifikant sind hingegen die Zusammenhänge mit den anderen Deliktsformen, die (extremistisches Material weniger; Cyber-Attacken mehr) deutlich positiv korrelieren. Es ist zu ergänzen, dass das hier nur bivariate Korrelationen sind. Die Zahlen sagen nichts über Kausalität oder Wechselwirkung aus. Dies ist besonders gut an Schwedisch und Niederländisch zu sehen, die zwar auch signifikant hoch korreliert sind, jedoch nur weil die betroffenen Bevölkerungsgruppen oft mehrere Sprachen sprechen. Vor allem Deutsch, Englisch und Französisch sind deswegen bei Muttersprachlern als Zweitsprachen bzw. in Grenzregionen bspw. zwischen Niederlanden und Deutschland verbreitet. Ein Umstand, der die Korrelation verfälscht. Zudem war in den Analysen meiner Abschlussarbeit zu beobachten, wie schnell demographische Effekte verschwinden, wenn sie in multivariaten Regressionsmodellen herangezogen werden.
Fazit und Schlussfolgerung
Doch wozu dieser Aufwand? Worauf ich hinaus will, ist, dass Sprachen offenbar als Grenzregime kultureller Räume auch das Internet aufteilen. Vertraut man der Routine Activity Theory (RAT) nach Cohen & Felson (1979) kommt es zu kriminellen Handlungen nur dort, wo sich Opfer als auch Täter (ohne einen Wächter) treffen. Dieses Bild funktioniert in der realen Welt, wo Täter und Opfer einander sehen, anfassen und begegnen können. In sogenannten „virtuellen Räumen“ ist das aber nicht unbedingt der Fall. Gerade bei E-Mails fehlt diese Komponente des persönlichen Kontakts. Trotzdem: Woher auch immer die Täter die E-Mail-Adressen beziehen; sie verstehen es ihre Opfer zu überzeugen. Sie verleiten sie einen Button zu drücken, einem Link zu folgen, eine Datei herunterzuladen oder/und zu öffnen. Doch dafür ist ein Schauspiel nötig, dass bei E-Mails lediglich auf den Austausch von schriftlichen Nachrichten beschränkt ist und somit Sprachkenntnisse über Rechtschreibung, Grammatik und Semantik erfordert. Eine Fähigkeit, über die Übersetzungsprogramme zwar verfügen, aber auch oft nur in einem begrenzten Rahmen. Bei Sprache handelt es sich also um eine Schlüsselkompetenz bestimmter delinquenter Handlungen.
Dass manche Sprachen mehr betroffen sind als andere, kann durch die Anzahl ihrer Nutzer und deren Leitmotive erklärt werden. Weit verbreitete Sprachen, wie Englisch (siehe Graphik oben), Deutsch oder Französisch, steigern offenbar das Risiko attackiert zu werden. Überraschend ist hingegen, dass es auch Sprachen gibt, die sicherer erscheinen als andere. Warum ist es also für russischsprechende Bevölkerungen augenscheinlich sicherer als für andere?
Dies zu evaluieren – dabei die am Beispiel Schwedisch und Niederländisch zu Tage getretenen Interferenzen in den Messungen herauszufiltern und belastbare Erkenntnisse zu generieren – bedarf weitergehender Analysen sowohl der der Opfer- als auch Täterkulturen. Das Verhalten dieser Gruppen innerhalb und außerhalb des Internets sowie ihrer Einstellungen zu den neuen Technologien und der damit verbundenen Kriminalität sollten uns mehr interessieren als das bloße Starren auf vermeintlich (un)sichere Technologien. Unschwer ist damit zu erkennen, dass in naher Zukunft nicht nur statistische Analysen wie diese, sondern vor allem qualitative Explorationen erfolgen müssen.
Literatur
Cohen, L. E., & Felson, M. (1979). Social Change and Crime Rate Trends: A Routine Activity Approach. American Sociological Review, 588-608.
European Commission (2012): Eurobarometer 77.1 (2012). TNS OPINION & SOCIAL, Brussels [Producer]. GESIS Data Archive, Cologne. ZA5597 Data file Version 2.0.0, doi:10.4232/1.11481
European Commission (2013): Eurobarometer 77.2 (2012). TNS OPINION & SOCIAL, Brussels [Producer]. GESIS Data Archive, Cologne. ZA5598 Data file Version 3.0.0, doi:10.4232/1.11696
Symantec (2014): Internet Security Threat Report. Appendix 2014. 2013 Trends, Volume 19, Published April 2014, URL: http://www.symantec.com/security_response/publications/threatreport.jsp
Titelgrafik By Rock1997 (Own work) [GFDL or CC-BY-SA-3.0-2.5-2.0-1.0], via Wikimedia Commons
{kind=link}
„Zur Analyse verwendete ich in der Abschlussarbeit Stata SE. Da dies eine komplett neue Auswertung sein soll, kommt dieses Mal PSPP zum Einsatz, welches eine Open-Source Alternative noch entsprechen sie immer den von Europa präzise definierten Vorgaben. Das gleiche gilt für Sprachkenntnisse, die nicht gemäß Common European Framework of Reference for Languages: Learning, Teaching, Assessment (CEFR) erfasst werden, sondern mittels grober und unreflektierter Selbsteinschätzung abgefragt werden. Damit ist es nicht möglich zu bestimmen, ob die Sprachkenntnisse eines/er Befragten bspw. auf Level C1 oder A3 sind. Und es ist auch nicht möglich weder die durchschnittlichen Sprachkenntnisse noch die Viktimierungsraten je Region noch irgendwelche anderen Daten mit den offiziellen Eurostat-Daten zu kartieren. Allerdings schafft TNS mit ca. 1000 Befragungen pro Mitgliedsland eine riesige Datenbasis, aufgrund derer qualitativ gute Hochrechnungen auf europäischem Level gemacht werden können. Mehr kann ein chronisch unterfinanzierter Masterstudent nicht verlangen.“
Der Absatz steht irgendwie zweimal im Text.
UPDATE:
Ups! Da ist mir bei der Übertragung wohl ein Unglück passiert. Der Fehler sollte jetzt behoben sein. Danke Mutter für den Hinweis.
Übrigens stelle ich bei Bedarf jedem meine Syntax zur Verfügung. Hierfür einfach das Kontaktformular ausfüllen, dann versende ich die *.sps-Datei per Mail.